
こんばんはー、ウチダです。
明日の株価を精度良く分析できたら、ひと儲けできそうだと思いませんか?
私は長期投資家ですが、短期でも安全に儲かるならチャレンジしたいと考えています。
でも、テクニカル分析は難しいので、正直苦手です。
そこでプログラミングで株価の予測をしてポジションをとろうと考えました。
今回はプログラミング言語Pythonの機械学習によって株価の予測をした話を紹介します。
プログラミング言語Pythonの機械学習を使って株価の予測をしよう

今回はガル子さんとボイ男くんの家庭でお話します。
(参考:ガル子さんが長期投資を始めた話)
ボイ男くんは短期でお金持ちになりたいと考えています。
お金持ちになるのに10年も20年も待っていられないよ。
ぼくは明日お金持ちになりたいんだ!
寛大なガル子さんは、お小遣いの範囲ならチャレンジしていいと許可を出しました。
失敗はしたくないからな。
どうやって確度を高めようか・・。
ボイ男くんが投資の情報収集をしていると、YouTubeでこんな動画を見つけました。
プログラミングで株価の予測をするのか!
機械学習ってなんかすごそう♪
さらにネットで調べると解説記事も発見しました。
(参考:Stock Price Prediction Using Python & Machine Learning)
プログラミングで株価の予測ができるようになったら
すぐにお金持ちになれるんじゃ・・!
ボイ男くんはプログラミングで株価の予測をする方法を勉強しました。
プログラミングで株価予測するために機械学習を使ってみよう!

ボイ男くんは趣味でプログラミング言語Pythonを使ったことがありました。
ただ難しいことはよくわかりません。
車を作れることと、車に乗れることは全く別物。
とりあえず動かせるようになったらいいだろう。
難しい話はすべてすっ飛ばして株価の予測プログラムを作ることにしました。
今回はiPhoneで有名なアップル社の株価を予測することにしました。
過去の60日間の終値から、将来の61日目の終値を予測するプログラムです。
イメージはこんな感じです。

どのぐらい予測できるのか、テストした結果がこちらです。
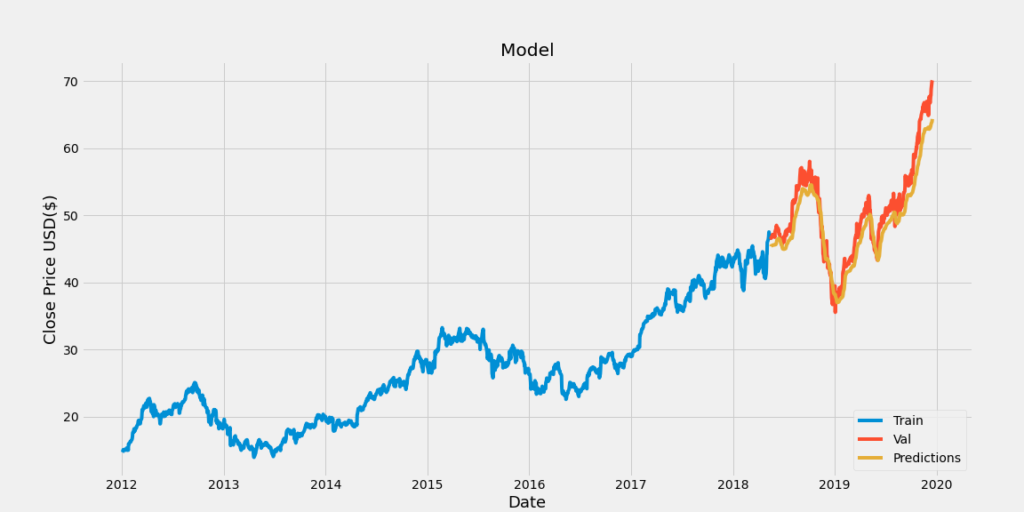
結構いいじゃん!
なかなかの予測精度です。
人が当てずっぽうに予想するよりはるかに良いでしょう。
機械学習による株価の予測に使用したコードはこちらです。
#必要なライブラリのインポート
import math
import pandas_datareader as web
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, LSTM
import matplotlib.pyplot as plt
import datetime
plt.style.use('fivethirtyeight')
#Yahoo financeからアップル社の株価のデータを引用する
df = web.DataReader('AAPL', data_source='yahoo', start='2012-01-01', end='2019-12-17')
#Show the data
df.head()
#終値をグラフ化する
plt.figure(figsize=(16,8))
plt.title('Close Price History')
plt.plot(df['Close'])
plt.xlabel('Date',fontsize=18)
plt.ylabel('Close Price USD ($)',fontsize=18)
plt.show()
#dfから終値だけのデータフレームを作成する。(インデックスは残っている)
data = df.filter(['Close'])
#dataをデータフレームから配列に変換する。
#https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.values.html
dataset = data.values
#トレーニングデータを格納するための変数を作る。
#データの80%をトレーニングデータとして使用する。今回は2003のうち1603をトレーニングに使用する
#math.ceil()は小数点以下の切り上げ
#https://note.nkmk.me/python-math-floor-ceil-int/
training_data_len = math.ceil(len(dataset) * .8)
#データセットを0から1までの値にスケーリングする。
#https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html
scaler = MinMaxScaler(feature_range=(0, 1))
#fitは変換式を計算する
#transform は fit の結果を使って、実際にデータを変換する
#https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html#sklearn.preprocessing.MinMaxScaler.fit_transform
scaled_data = scaler.fit_transform(dataset)
#fit,transfrom,fit_transformの違い
#https://mathwords.net/fittransform
#これを行うのは、データをニューラルネットワークに渡す前にスケーリングするのが一般的に良い習慣だからです。
'''
61番目の終値を予測するため、過去60日間の終値を含むトレーニングデータセットを作成します。
x_trainデータセットの最初の列には、インデックス0からインデックス59までのデータセットの値(合計60個の値)が含まれ、
2番目の列にはインデックス1からインデックス60までのデータセットの値(60個の値)が含まれます。
y_trainデータセットには、最初の列のインデックス60にある61番目の値と、
2番目の値のデータセットのインデックス61にある62番目の値が含まれます。
'''
len(scaled_data)
#正規化されたデータセットを作る。データ数はトレーニングデータ数にする
train_data = scaled_data[0:training_data_len, :]
len(train_data)
#データをx_trainとy_trainのセットに分ける
x_train = []
y_train = []
for i in range(60, len(train_data)):
x_train.append(train_data[i-60:i, 0])
y_train.append(train_data[i, 0])
#[i:j]の場合、j-1までが抽出される
'''
x_train = (array([60コ]), array([60コ]), ・・・)と60コの行データが1543コ入っている
y_train = (a,b,c,・・・)と1543コのデータが入っている
'''
'''
独立トレーニングデータセット「x_train」と従属トレーニングデータセット「y_train」をnumpy配列に変換して、
LSTMモデルのトレーニングに使用できるようにします。
'''
x_train, y_train = np.array(x_train), np.array(y_train)
'''
x_train = array([[a,b,c,・・・],
[d,e,f,・・・],
・・・])と60列のデータが1543行入っている。
y_train = array([a,b,c,・・・])と1543列のデータが1行に入っている。
'''
'''
データを[サンプル数、タイムステップ数、および特徴数]の形式で3次元に再形成します。
LSTMモデルは、3次元のデータセットを想定しています。
'''
#LSTMに受け入れられる形にデータをつくりかえます
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
'''
https://note.nkmk.me/python-numpy-reshape-usage/
numpy.reshape(numpy.ndarray,(a, b, c))
データをa個のndarrayに分ける
その分けられたデータはb行、c列の形状になる
x_train = array([[a],
[b],
[c],
・
・
・]) と60行1列のデータを1543コ作る
'''
#LSTMモデルを構築して、50ニューロンの2つのLSTMレイヤーと2つの高密度レイヤーを作成します。(1つは25ニューロン、もう1つは1ニューロン)
#Build the LSTM network model
model = Sequential()
model.add(LSTM(units=50, return_sequences=True,input_shape=(x_train.shape[1],1)))
model.add(LSTM(units=50, return_sequences=False))
model.add(Dense(units=25))
model.add(Dense(units=1))
#平均二乗誤差(MSE)損失関数とadamオプティマイザーを使用してモデルをコンパイルします。
model.compile(optimizer='adam', loss='mean_squared_error')
'''
トレーニングデータセットを使用してモデルをトレーニングします。
フィットはtrainの別名であることに注意してください。
バッチサイズは、単一のバッチに存在するトレーニング例の総数であり、
エポックは、データセット全体がニューラルネットワークを前後に渡されるときの反復回数です。
'''
#Train the model
model.fit(x_train, y_train, batch_size=1, epochs=1)
#Test data set
#test_dataはtraining_dataから60コ減らしたデータ
#つまり60日間の終値から将来の終値を予測するためにtest_dataを用意する
test_data = scaled_data[training_data_len - 60: , : ]
#Create the x_test and y_test data sets
#1603行目以降のデータをすべてy_testに入れる (この場合は終値だけ),
#つまり 2003 - 1603 = 400 行のデータになる
x_test = [] #予測値をつくるために使用するデータを入れる
y_test = dataset[training_data_len : , : ] #実際の終値データ
for i in range(60,len(test_data)):
x_test.append(test_data[i-60:i,0]) #正規化されたデータ
'''
次に、独立したテストデータセット「x_test」をnumpy配列に変換して、
LSTMモデルのテストに使用できるようにします。
'''
#Convert x_test to a numpy array
x_test = np.array(x_test)
#60列のデータが400行入ったものになる
'''
Reshape the data to be 3-dimensional in the form [number of samples, number of time steps, and number of features].
This needs to be done, because the LSTM model is expecting a 3-dimensional data set.
'''
#Reshape the data into the shape accepted by the LSTM
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
#60行1列のデータが400コ入った形に変換する
#Now get the predicted values from the model using the test data.
#Getting the models predicted price values
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions) #Undo scaling
'''
Get the root mean squared error (RMSE),
which is a good measure of how accurate the model is.
A value of 0 would indicate that the models predicted values match the actual values from the test data set perfectly.
The lower the value the better the model performed.
But usually it is best to use other metrics as well to truly get an idea of how well the model performed.
'''
#Calculate/Get the value of RMSE
rmse = np.sqrt(np.mean(predictions - y_test) ** 2)
rmse
#Let’s plot and visualize the data.
#Plot/Create the data for the graph
train = data[:training_data_len]
valid = data[training_data_len:]
valid['Predictions'] = predictions#Visualize the data
plt.figure(figsize=(16,8))
plt.title('Model')
plt.xlabel('Date', fontsize=18)
plt.ylabel('Close Price USD ($)', fontsize=18)
plt.plot(train['Close'])
plt.plot(valid[['Close', 'Predictions']])
plt.legend(['Train', 'Val', 'Predictions'], loc='lower right')
plt.show()ボイ男くんはいろんな資産の価格に試してみました。
df = web.DataReader('AAPL', data_source='yahoo', start='2012-01-01', end='2019-12-17')
の'AAPL'を他のコードに変えると機械学習ができます。
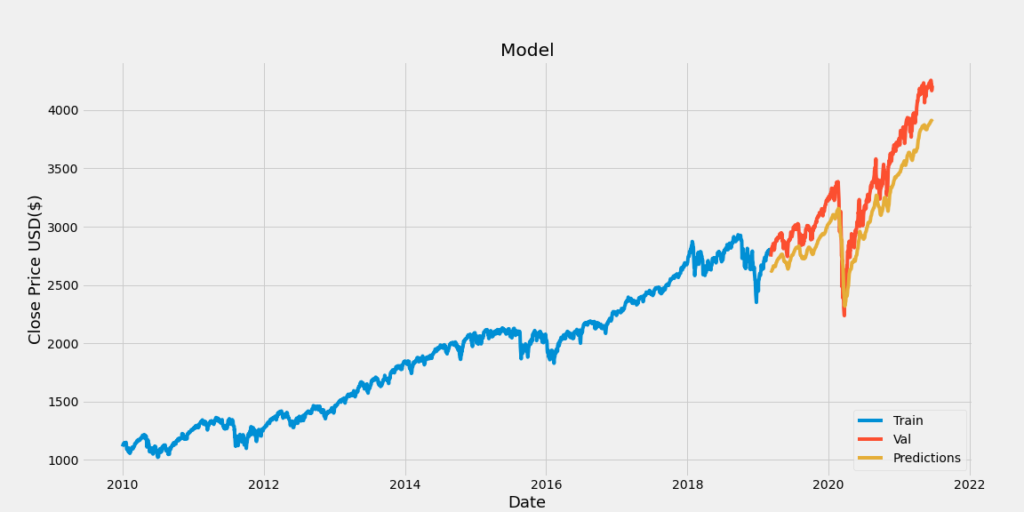
S&P500
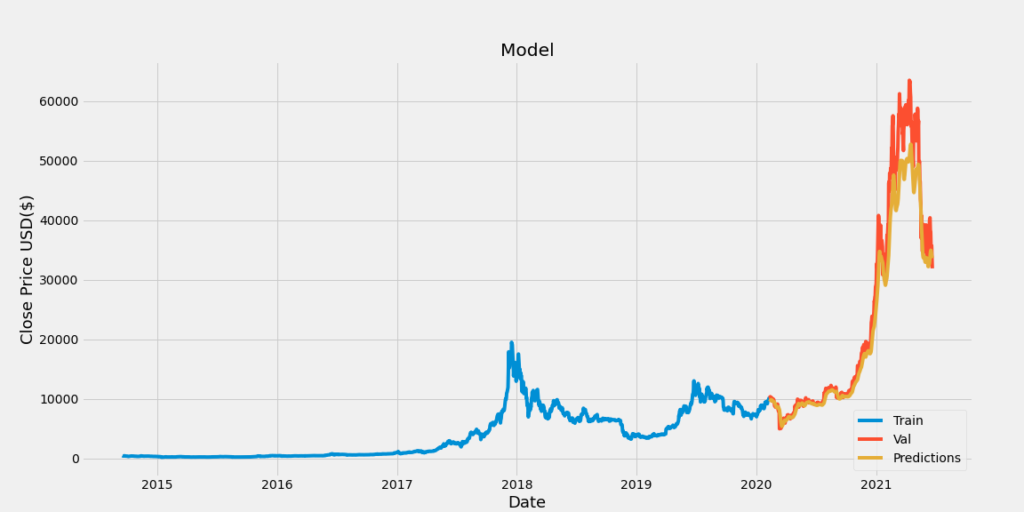
ビットコイン
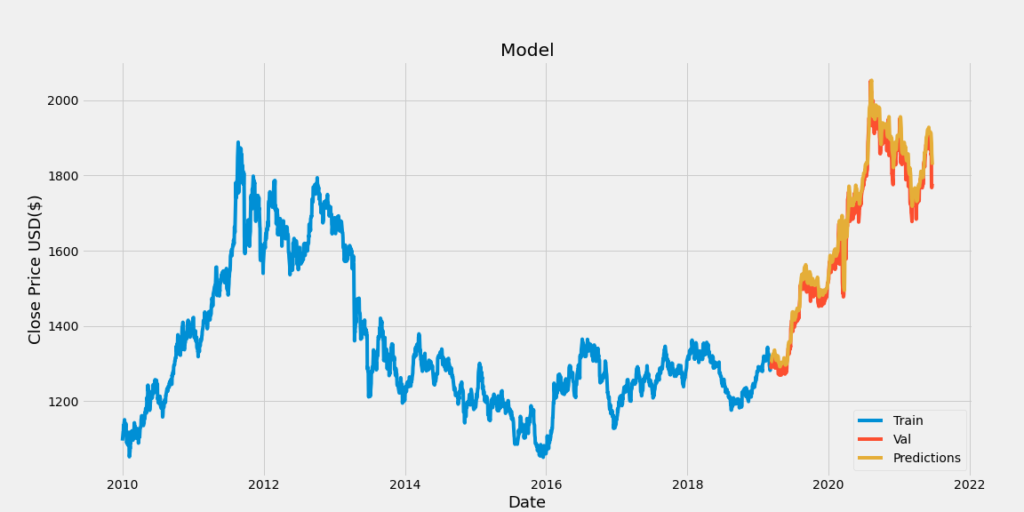
金
銀
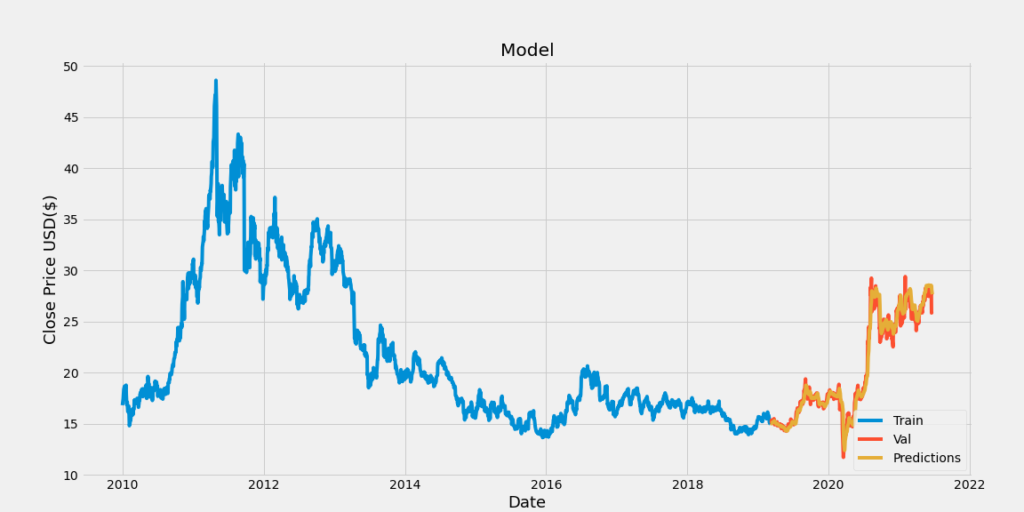
さまざまな資産の価格予測をした結果、これも予測精度がまずまずの結果でした。
ボイ男くんはさらに機械学習を勉強して投資でひと儲けしようと考えたのでした。
つづく
今回使用したプログラムはこちら↓
★pythonによる投資の分析を学ぶのにおすすめの本
